On Monday, June 23rd, I went to Botafogo in Rio de Janeiro to take part in a job interview scheduled for 4:00 P.M. I arrived there 3:10 P.M. so that I could have some time to relax a little bit.
The girl that conducted the interview was Roberta Furtado de Vasconcelos. She is a psychologist working for the human department at Oi. Oi is one of the biggest telecommunications players here in Brazil.
The job interview was fair and I was asked about some of the technologies that the job requires such as object oriented programming, Unix OS, the level of proficiency regarding the English language, etc.
We talked for about 45 minutes and one of the questions that I think was difficult to answer is: How much are you willing to earn? Wouldn't it be better if the company specified how much it wants to pay? It is complicated to answer such a question given the fact that you don't know how much the company is willing to pay for that specific position. I had already looked a salary table in a famous local IT magazine site called INFO online. It helped while answering this question.
Roberta said that the job interview process is composed of two interviews. The next one is going to take place soon if I happen to pass to the second round, that is, the first interview was just one more filter.
Let's see what happens next. If it happens I'll post here some notes about the second part of the interview process.
The crescent demand for enterprise management software has as key factor big companies, which need to manage millions of records trying with that: find a better way of working with so great amount of information available in their huge databases and get to the target of their business.
Between the most used software for enterprise management are the ones that lie in one of the following main categories:
Resources planning in a company (ERP) include or try to include all the company’s data and processes in a unified system. A typical ERP system will use multiple software and hardware components to achieve integration. A key ingredient for most ERP system is the use of a unified database to store the data from the various modules of the system.
CRM
Customer relationship management uses software products developed to help the companies in the construction and keeping of a good relationship with their clients. This is done through the storage of information of each client in an efficient and intelligent way. CRM is a general term that encompasses concepts used by the companies to manage their clients and includes capture, storage and analysis of data, suppliers, partners and internal processes information.
SCM
Supply chain management is the process of planning, implementing and controlling the operations of the supply chain to the highest efficiency degree possible. SCM includes all the transport logistics and storage of raw material and ready products from the origin to the destiny consumption market.
BSC
Balanced scorecard or scoreboard is a concept used to measure if the activities of a company are yielding expected results in terms of the strategic vision. Its focus isn’t only the financial result but also human questions. It helps in the provisioning of a more comprehensive vision of an organization what in its turn helps the companies to act according to the best way possible in a long term basis.
How is it used?
All these software work integrated.
The chairman, VP, CFO, CEO, CIO, CTO, etc., simply sat down in front of their computer and request a report. The systems then combine the data stored in unified databases, which have all the company’s historical data using technologies such as OLAP and OLTP. Business intelligence (BI), artificial intelligence (AI), data mining, etc, are concepts extensively applied to do the junction of enterprise data.
It has all to do with relevant data and how to better combine them through (SQL queries) to extract useful information. Information = processed data = money! :-)
My computer engineering final project verses about LINQ (Language Integrated Query), that is, the integration of the query language (SQL) into the programming language (specifically C#). It's a good starting point for those that wanna learn the principles of working with queries to extract useful information from databases.
What to expect from the future?
The good part of it is that this market is growing in a fast pace. This way, a lot of job opportunities are emerging.
I particularly have interest in this field: databases, computer networks, BI, HPC, etc. My area of specialization will be for sure system analysis with focus on software engineering and infrastructure.
I expect to work in this field in a near future. It’s really interesting and challenging because there are always details that can be improved, optimized.
Information management (IM) is the key to the proper organization of a company. If a company organizes its data, its income will grow. It’s a proved fact.
Just as a note: one alarming factor that can arise is the security related to all the information of a company what creates the field of information security.
A new area that is attracting attention nowadays is parallel computing, most precisely, high performance computing, which is other very important factor when dealing with huge sets of data as is the case of enterprise management software.
Parallel processing will be the focus on the next years because it is necessary for the next step toward fastest software processing. Long live the dual-quad (many) core processors.
This post is related to one of the best coursework I've done during the computer engineering course. I'm really proud of it. It was the cornerstone in my programming career and helped me choose an area to put my efforts from that moment on. I was in the 5th term out of 10 (3rd year of the course out of 5 more exactly). The discipline was Programming Languages.
This subject is fantastic and is used extensively throughout the the computer science field.
First I'll give a short description about the Quicksort and Binary Search algorithms and then I'll present the work that I and my dear brother in faith Wellington Magalhães Leite did.
Quicksort
Quicksort is a well-known sorting algorithm developed by C. A. R. Hoare. Typically, quicksort is significantly faster in practice than other sorting algorithms, because its inner loop can be efficiently implemented on most architectures.
Binary Search
A binary search algorithm (or binary chop) is a technique for finding a particular value in a sorted list. It makes progressively better guesses, and closes in on the sought value by selecting the median element in a list, comparing its value to the target value, and determining if the selected value is greater than, less than, or equal to the target value. A guess that turns out to be too high becomes the new top of the list, and a guess that is too low becomes the new bottom of the list. Pursuing this strategy iteratively, it narrows the search by a factor of two each time, and finds the target value.
Our paper
Our paper is entitled Quicksort and Binary Search Algorithms. You can get a copy at the end of this post.
Without more ado, see its abstract bellow:
Sorting and searching algorithms are a core part of the computer science area. They are used throughout the programming work when you need to sort a set of data and when you need to search for a specific record (key) present in such set of data.
Quicksort is one of the fastest (quick) sorting algorithms and is most used in huge sets of data. It performs really well in such situations.
Binary search tree is one of the fastest searching algorithms and is applied in a sorted set of data. It reduces the search space by 2 in each iteration, hence its name (binary).
In this paper we present the intrinsic nature of each algorithm as well as a functional implementation of such algorithms in the C++ programming language.
Keywords: quicksort, binary search, sorting algorithms, searching algorithms, c++ programming language
CONTENTS
1 INTRODUCTION 6
1.1 Objective 6
1.2 Definition 6
1.2.1 Sorting algorithms 6
1.2.2 Searching algorithms 7
2 DEVELOPMENT 8
2.1 Quicksort algorithm (swapping and partitioning) 8
2.1.1 Detailed steps 8
2.2 Binary search algorithm 9
2.3 Studying the efficiency of the methods 9
2.3.1 The big O notation 9
2.3.2 Quicksort efficiency 10
2.3.2.1 The best and the worst case 10
2.3.2.2 Comparison with other sorting algorithms 11
2.3.3 Binary search efficiency 11
3 APPLICATION 12
3.1 Quicksort implementation 12
3.2 Binary search implementation 13
4 CONCLUSION 14
5 REFERENCES 15
Words of wisdom
As I mentioned, during the 5th term of the computer engineering course our teacher Marcus Vinicius Carvalho Guelpeli selected some sorting and searching algorithms to pass to the class as a coursework.
The coursework should be done in pairs and each pair should select a sorting and searching algorithm to compose a paper about it. We selected the quicksort and the binary search algorithms. The teacher advised us that these weren't the easy ones. I just thought: that's what I want. I don't want the easy ones. Why? Because if you get just the easy problems I'll never understand something that demands a more deep approach and every time a difficult task is given you'll tend to refuse it. What's the best thing to do? Just accept the challenge and go for it. Chances are you'll succeed. That's just what happened with us.
We haven't just written about the quicksort and the binary search, we implemented it and presented it to the class in a power point presentation. The teacher liked it so much that our grade was the highest possible! :-) In the end what did we feel? An amazing feeling. Something such that the work had been done and we learned a lot from it. That’s what a college and even an online computer science degree program is supposed to do. Give you the subjects and motivate you; teaching the basic so that you can dig up the more difficult aspects of the subject being taught.
So what's next? Well, I'll explain how we implemented the quicksort and the binary search algorithms.
Quicksort and Binary search algorithms implementation in C++
One of the things that I've always listened to was about code reuse. You search for something already implemented so that you just haven't to reinvent the wheel. Of course you'll complement or even adapt the available code to your situation. That was what we did. I found some code for the quick sort at MSDN and implemented the binary search one. Unfortunately the page at MSDN isn't available anymore. It's been three years since I hit that page.
I wanted a way of measuring the time elapsed so that we could compare the efficiency of both methods when they were fed with different input data sets. The input is nothing more than a text file .txt full of numbers in this case. Can be any data you want. Each test case we passed a text file with different random numbers and different quantity of numbers. For example, in a test case we passed a file named 2500.txt, that means 2500 random numbers. In another test case we passed other file named 7500.txt as so on. I think you got it. Doing so we could compare how well the algorithms were performing.
To generate the random numbers we used an Excel spreadsheet with the formula =RAND()*1000000. For each set of data we generated new numbers and copied and pasted those numbers into the text files that are the input for our program. During a coursework as this one we get to learn everywhere, even a new formula in Excel. It's really good. ;-)
Again, I searched for a timing class that I could reuse with the code and for sure I found it. I didn't use it at all but I used it to learn about how to measure time in C++. It's amazing how fast you can implement something. Much of the things you need related to programming are already implemented. You just have to search for it as is what you're doing here, I think! You searched for the subject of this post and here you are seeing something implemented. Try to learn from it and just don't copy the entire work and think that you know about it. It's wrong. Try to understand what the code is doing. Dive into the theory because it explains the inner essence.
The code that follows is well commented which is something every developer should do. You see, it was three years ago when we worked with this code. Today it's difficult to remember every step I took. The comments helped me to remember almost everything.
Bellow I present the quick sort method we borrowed from MSDN (we adapted it to fit our case). Note the use of the Partition method (explained in the accompanying paper):
// QuickSort implementation
void QuickSort(char** szArray, int nLower, int nUpper)
{
// Check for non-base case
if(nLower < nUpper)
{
// Split and sort partitions
int nSplit = Partition(szArray, nLower, nUpper);
QuickSort(szArray, nLower, nSplit - 1);
QuickSort(szArray, nSplit + 1, nUpper);
}
}
// QuickSort partition implementation
int Partition (char** szArray, int nLower, int nUpper)
{
// Pivot with first element
int nLeft = nLower + 1;
char* szPivot = szArray[nLower];
int nRight = nUpper;
// Partition array elements
char* szSwap;
while(nLeft <= nRight)
{
// Find item out of place
while(nLeft <= nRight && strcmp (szArray[nLeft], szPivot) <= 0)
nLeft = nLeft + 1;
while (nLeft <= nRight && strcmp (szArray[nRight], szPivot) > 0)
nRight = nRight - 1;
// Swap values if necessary
if(nLeft < nRight)
{
szSwap = szArray[nLeft];
szArray[nLeft] = szArray[nRight];
szArray[nRight] = szSwap;
nLeft = nLeft + 1;
nRight = nRight - 1;
}
}
// Move pivot element
szSwap = szArray[nLower];
szArray[nLower] = szArray[nRight];
szArray[nRight] = szSwap;
return nRight;
}
Now see the binary search method implementation that we did:
int BinarySearch(char** szArray, char key[], int nLower, int nUpper)
{
// Termination case
if(nLower > nUpper)
return 0;
int middle = (nLower + nUpper) / 2;
if(strcmp(szArray[middle], key) == 0)
return middle;
else
{
if(strcmp(szArray[middle], key) > 0)
// Search left
return BinarySearch(szArray, key, nLower, middle - 1);
// Search right
return BinarySearch(szArray, key, middle + 1, nUpper);
}
}
The next ones are the method prototypes and the main entry point that calls a menu. According to the user passed parameters we call the quicksort and the binary search methods:
// Function prototypes
void Menu(void);
void QuickSort(char** szArray, int nLower, int nUpper);
int Partition(char** szArray, int nLower, int nUpper);
int BinarySearch(char** szArray, char key[], int nLower, int nUpper);
// Application initialization
void main(void)
{
char op;
do
{
Menu();
printf("\n\nDo you wanna a new QuickSort? Y/N");
op = getche();
if(islower(op))
op = toupper(op);
}
while(op == 'Y');
}
void Menu(void)
{
// Clear screen
system("CLS");
// Control execution time
clock_t initial, final;
// Print startup banner
printf("\nQuickSort C++ Sample Application\n");
printf("Copyright (c)2001-2002 Microsoft Corporation. All rights reserved.\n\n");
printf("MSDN ACADEMIC ALLIANCE [http://www.msdnaa.net/]\n\n");
printf("BinarySearch C++ Sample Application\n");
printf("Copyright (c)2005 Leniel Braz de Oliveira Macaferi & Wellington Magalhaes Leite.\n");
printf("UBM COMPUTER ENGINEERING - 5TH SEMESTER [http://www.ubm.br/]\n\n");
// Describe program function
printf("This program example demonstrates the QuickSort and BinarySearch algorithms by\n");
printf("reading an input file, sorting its contents, writing them to a new file and\n");
printf("searching on them.\n\n");
// Prompt user for filenames
char szSrcFile[1024], szDestFile[1024];
printf("Source: ");
gets(szSrcFile);
printf("Output: ");
gets(szDestFile);
// Read contents of source file
const long nGrow = 8;
long nAlloc = nGrow;
long nSize = 0;
char** szContents = new char* [nAlloc];
char szSrcLine[1024];
FILE* pStream = fopen(szSrcFile, "rt");
while(fgets(szSrcLine, 1024, pStream))
{
// Trim newline character
char* pszCheck = szSrcLine;
while(*pszCheck != '\0')
{
if(*pszCheck == '\n' && *(pszCheck + 1) == '\0')
*pszCheck = '\0';
pszCheck++;
}
// Append to array
szContents[nSize] = new char [strlen(szSrcLine) + 1];
strcpy(szContents[nSize], szSrcLine);
nSize = nSize + 1;
if(nSize % nGrow == 0)
{
// Resize the array
char** szPrev = szContents;
nAlloc += nGrow;
szContents = new char* [nAlloc];
memcpy(szContents, szPrev, nSize * sizeof(char*));
delete szPrev;
}
}
fclose (pStream);
initial = clock();
// Pass to QuickSort function
QuickSort(szContents, 0, nSize - 1);
final = clock();
// Write sorted lines
pStream = fopen (szDestFile, "wt");
for(int nIndex = 0; nIndex < nSize; nIndex++)
{
// Write line to output file
fprintf (pStream, "%s\n", szContents[nIndex]);
}
fclose (pStream);
// Report program success
printf("\nThe sorted lines have been written to the output file.\n\n");
// QuickSort execution time
double duration = (double)(final - initial) / CLOCKS_PER_SEC;
printf("The QuickSort execution time was: %2.9lf s = %.0lf ms = %.0lf \xE6s\n\n", duration, duration * 1000, duration * 1000000);
char op = '\0';
do
{
printf("Do you wanna a BinarySearch to locate a specific key? Y/N");
op = getche();
if(islower(op))
op = toupper(op);
if(op == 'Y')
{
printf("\n\nType the key you want to search for: ");
char key[1024];
gets(key);
initial = clock();
if(BinarySearch(szContents, key, 0, nSize - 1))
{
final = clock();
duration = (double)(final - initial) / CLOCKS_PER_SEC;
printf("\nKey found!\n\n");
printf("The BinarySearch execution time was: %2.9lf s = %.0lf ms = %.0lf \xE6s\n\n", duration, duration * 1000, duration * 1000000);
}
else
{
final = clock();
duration = (double)(final - initial) / CLOCKS_PER_SEC;
printf("\nKey not found!\n\n");
printf("The BinarySearch execution time was: %2.9lf s = %.0lf ms = %.0lf \xE6s\n\n", duration, duration * 1000, duration * 1000000);
}
}
else
{
// Deallocate entire array
for(int nIndex = 0; nIndex < nSize; nIndex++)
// Delete current array element
delete szContents[nIndex];
delete szContents;
szContents = NULL;
}
}
while(op == 'Y');
}
Enter the name of a file that contains unsorted data;
Use the sample files included in the .ZIP package as: 1000.txt and 2500.txt;
In the command line "Source", type: 1000.txt;
In the command line "Output", type a name to the file that will be sorted. e.g.: sorted.txt;
After the sorting process, choose if you want or not to execute a Binary Search. If yes, provide a value to be searched. If not, choose if it is or not desired to execute a new Quicksort.
Postscript:
- To generate random numbers, use the file Random numbers generator.xls file;
- The file QuicksortBinarySearch.cpp contains the source code. The same can be used freely. Mention the authors.
Efficiency comparison
For the sake of comparison I've run some test cases with different input files. See the result in the table that follows:
Quicksort and Binary search performance
n
File name
File size (bytes)
Timing (milliseconds)
Quicksort
Binary search
10000
10000.txt
122.880
16
0
25000
25000.txt
200.704
78
0
50000
50000.txt
401.408
219
0
75000
75000.txt
602.112
360
0
100000
100000.txt
802.816
516
0
It's important to note that the time the quicksort takes appears to be longer but it is not. Why? Because the the program needs to read the file content and write the sorted data back to the output file so that it appears to take longer than the milliseconds shown on the above table. The timing functions just operate while the quicksort is running.
For the the binary search key I've input a value localized in the beginning of the sorted file, in the middle and in the end. There was no time changes. The binary search found the key I entered with a time less than (0 µs - microsecond). I have an AMD Athlon XP 2400 with 512 MB RAM.
SnagIt is one of few software products that really amazes me. Why? Because it lets me get any kind of screenshot.
With SnagIt I'm able to capture, edit, and share in this blog or wherever exactly what I see on my screen. I can even record any screen activity on my desktop.
I've been a loyal user of SnagIt for more than 4 years now and I recommend it for anyone interested in getting screenshots from their computer screen.
The range of possibilities when it comes to capturing a screenshot with SnagIt is vast.
In the picture bellow you can see the different options/profiles you can chose to capture a screenshot:
To capture the above picture I used the Window profile.
You can capture just a region of the screen as a menu bar or task bar, the entire window, the full screen, a scrolling window or web page that doesn't fit in the window and can even keep the web page links. There are various profiles to choose from.
You can include the mouse cursor in the screenshot so that it's visible what is the action you are emphasizing when capturing the screenshot.
You can output the screenshot to the clipboard, a file, e-mail, to office programs, etc. The output types available are the ones shown on the following picture:
When you're ready, just click on the big read circle with a camera in the main SnagIt window. After doing it SnagIt gets the screenshot and takes you to the SnagIt Editor where it's possible to make customizations on the screenshot just captured.
See the SnagIt Editor:
It's possible to highlight specific areas of the screenshot, add effects and actions to the screenshot and change the size and the color of the same.
SnagIt is a rich product with lots of features. It's impossible to cover all of them in just a blog post. The better thing to get started is to use it to explore all its richness. Once you're familiar with it you'll take advantage of it.
Where do I get SnagIt? SnagIt is produced and commercialized by TechSmith that specializes in software products for screen capturing/recording in ways that help us "the users" to communicate more clearly, create engaging presentations for diverse audiences, and analyze product usability and experience.
One of its other products is Camtasia Studio that easily record the screen to create training, demo, and presentation videos. It's a must have to those that frequently need to record instructional videos as is the case of IT professionals.
If you want to use Blogger’s built in function take a look in this question at StackOverflow. Updated on 08-10-2010
I just wanted to backup my blogger posts. I searched for a tool that could automate the process and fortunately I found a pretty good piece of software that does just that. Its name is Blogger Backup Utility.
The software enables you to backup your posts with a high degree of customization. You can backup all the blogs you have. Each one will have its own backup settings.
You can choose if you want to save posts' comments, in what format (one AtomXML file per post or all the posts in a single file) to save the posts, if you want only the most recent posts or the ones included in the specified data range.
See the screenshot of the main window bellow:
Clicking on the button Backup File Naming you'll have the chance of specifying the naming options for the backup files.
There are to configurable options: Folder Name Options and Post File Name Options.
In Folder Name Options you can configure the directory structure in which your posts will be saved.
In Post File Name Options you can configure the name of each post.
In both Folder Name and Post File Name, you can chose from a diverse array of patterns to form the name of the directory structure and posts.
See the screenshot of the Backup File Naming Options:
After setting up your blog configurations you can click the button Backup Post in the Main Window.
A progress bar on the status bar and list of processed posts will show you the backup process.
The inverse process is also possible, that is, to restore your blog posts, just click on Restore Posts in the Main Windows.
It's really simple, fast and efficient. It does what it's meant to do.
The app only backups in the Atom file format that is an XML file.
Bellow is the structure of the XML that represents the backup copy of this post:
The Blogger Backup utility is intended to be a simple utility to backup to local disk your Blogger posts.
Using the GData C# Library, the utility will walk backward in time, from your latest post to your last, saving each post to a local Atom/XML file.
I congratulated him and wrote on the project's page at CodePlex that the addition of the HTML format when saving the posts would be a good feature in case someone wanted to save the posts in an HTML fashion instead of XML.
I'm reading the book Expert F# by Don Syme et al. In chapter 3 - Introducing Functional Programming, pg. 29 is listed the F# Bitwise Arithmetic Operators. They are shown in Table 1:
Table 1. Bitwise Arithmetic Operators and Examples
Operator
Description
Sample
Use Result
&&&
Bitwise “and”
0x65 &&& 0x0F
0x05
|||
Bitwise “or”
0x65 ||| 0x18
0x7D
^^^
Bitwise “exclusive or”
0x65 ^^^ 0x0F
0x6A
~~~
Bitwise negation
~~~0x65
0xFFFFFF9a
<<<
Left shift
0x01 <<< 3
0x08
>>>
Right shift (arithmetic if signed)
0x65 >>> 3
0x0C
The sample given to help with the understanding of such operators is about an integer encoder. Read the sample statement:
The following sample shows how to use these operators to encode (signed) 32-bit integers into 1, 2, or 5 bytes, represented by returning a list of integers. Integers in the range 0 to 127 return a list of length 1.
The proposed solutions is:
let encode (n: int32) =
if (n >= 0 && n <= 0x7F)
then [ n ]
elif (n >= 0x80 && n <= 0x3FFF) then [ (0x80 ||| (n >>> 8)) &&& 0xFF;
(n &&& 0xFF) ]
else [ 0xC0; ((n >>> 24) &&& 0xFF);
((n >>> 16) &&& 0xFF);
((n >>> 8) &&& 0xFF);
(n &&& 0xFF) ]
As I have never spent time with code that handles individual bits I had a tough time to understand what was going on with this code. I didn't go further reading the book until I could understand the problem through and through. Obviously the problem statement is clear. The input and output is clearly stated. No doubt. The problem I had was to understand how the code was producing the output. What did I do? I spent some time reading about the bitwise operations. For sure I've studied it on college but I haven't practiced it programmatically through coding. I did lots of exercises about this matter but only analytically, that is, using sheets of paper. Sometimes it's good to write things down and be the processor for an instant! :-)
I executed the above code mentally and even wrote some test cases to make sure I was understanding the intrinsic aspects of it.
Bellow are the annotations I did to exercise the problem analytically. I provide them so that you can use the annotated calculations to better realize what's going on during the computations:
(* The following sample shows how to use Bitwise Operators to encode (signed) 32-bit integers into 1, 2, or 5 bytes, represented by returning a list of integers. Integers in the range 0 to 127 return a list of length 1: *)
let encode (n: int32) =
// from n >= 0 && n <= 127
if (n >= 0 && n <= 0x7F) then [ n ]
// from n >= 128 && n <= 16383 255
elif (n >= 0x80 && n <= 0x3FFF) then [ (n >>> 8)) &&& 0xFF;
(* 192 *) (* 255 *) (n &&& 0xFF) ]
else [ 0xC0; ((n >>> 24) &&& 0xFF);
((n >>> 16) &&& 0xFF);
((n >>> 8) &&& 0xFF);
(n &&& 0xFF) ]
(* Date: 05-08-2008
Hexa | Decimal | Binary
0x7F 127
0x80 128 10000000
0x3FFF 16383
0xFF 255 11111111
0xC0 192
e.g.: n = 7777 falls into the elif statement returning a list of [2 bytes]
1st byte 1111001100001 = 7777
0000000011110 (n >>> 8)
||| 10000000 = 128
--------
10011110 = 158
&&& 11111111 = 255
--------
10011110 = 158
2nd byte 1111001100001 = 7777
&&& 0000011111111 = 255
-------------
0000001100001 = 97
list = [158; 97]
e.g.: n = 100000 falls into the else statement returning a list of [5 bytes]
1st byte = 0xC0 = 192
2nd byte 11000011010100000 = 100000
000000000000000000000000 (n >>> 24)
&&& 11111111 = 255
-----------------
00000000000000000 = 0
3rd byte 11000011010100000 = 100000
00000000000000001 (n >>> 16)
&&& 11111111 = 255
-----------------
1 = 1
4th byte 11000011010100000 = 100000
00000000110000110 (n >>> 8)
&&& 011111111 = 255
-----------------
010000110 = 134
5th byte 11000011010100000 = 100000
&&& 00000000011111111 = 255
-----------------
00000000010100000 = 160
list = [192; 0; 1; 134; 160]
Reference: http://en.wikipedia.org/wiki/Bitwise_operation#AND *)
I definitely understood the code while I was writing the above annotations. So, what exactly do the bitwise operators do? Consider for example this fragment of the above F# code:
Reading the sequence of remainders from the bottom up gives the binary number 100110100101002. The subscript 2 is to say that this is a binary number representation (base 2).
Right shift operation
The bitwise operator >>> (right shift) is applied to the bits that represent the integer (decimal) value of n. By right shifting we in fact push zeros toward the right side of the string of bits. The once least significant bits of the representation are then discarded.
The code above will right shift the value 100110100101002 by 8, that is, 8 zeros will be inserted into the start of the string of bits pushing the least significant bits out of it. What we get is:
Bitwise "and" operation The bitwise operator &&& (bitwise “and”) is then applied to the result of the right shifting operation just executed. It does nothing and is used here just for the sake of exemplification. Therefore the next operation that will be performed is:
The comparison process is done in pairs of bits - 1 bit of each string of bits. When the bits that compose the pair are equal 1 the "and" operator outputs 1 otherwise 0.
As you can see the value remains the same after the bitwise "and" operation.
There is a case in which the bitwise "and" operator executes a different operation. The following line of code shows it:
(n &&& 0xFF)
Note that this time there's no right shifting operation. In this case what happens is:
The above operation is executed so that it's possible to isolate part of the string of bits. The binary representation is broken in chunks of bytes. 1 byte is equal 8 bits.
According to the problem statement. The integer value n will be encoded into 1, 2 or 5 bytes. To achieve this the right shift operator (>>>) and the bitwise "and" operator (&&&) are used so that each chunk of 8 bits is analyzed and then converted to a byte that'll then be represented by its integer value.
The first byte from left to right of n is 100110. Its second byte is 10010100.
The output list of the code would be: [100110; 10010100] = [38; 148]
The following is the screenshot of the real program being executed:
As you see the output matches the analytical reasoning exercised in this post.
Left shift bitwise operation The bitwise operator <<<(left shift) does just the opposite of the right one, that is, instead of pushing zeros toward the right of the string of bits it actually pushes zeros toward the left. This changes the most significant bits.
For example, the sample given on Table 1 is 0x01 <<< 3 that'll will output a result equal to 0x08. 0x0116 = 110 and 0x0816 = 810. You may be asking yourself: what are those 0x at the beginning of each value. It's the form used to represent an hexadecimal (base 16) inside the programming language.
Getting back to the point, let's get the binary representation of 110: it is 12. This way, left shifting by 3 we'll get:
0001 = 110 1000 = 810 = (1 <<< 3)
Bitwise "or" operation The bitwise "or" operator (|||) is the opposite of the "and" operator.
For example, the sample given on Table 1 is 0x65 ||| 0x18 that'll output 0x7D. 0x65 = 10110 and 0x1816 = 2410. 0x7D16= 12510. We have that 10110 = 11001012 and 2410 = 110002 . This way, applying the bitwise "or" operator we get:
Note that additional zeros were added to the second string of bits so that it has the same length of the first.
Again the operation is done by comparing pairs of bits. One of each string of bits at a time. When any of the bits that compose the pair are equal 1 the "or" operator outputs 1. The unique case in which the output is 0 is when both bits are equal 0.
Bitwise “exclusive or” or XOR operation The bitwise "exclusive or" operator (^^^) outputs 1 if the bits being compared are different or 0 if they are equal.
For example, the sample given on Table 1 is 0x65 ^^^ 0x0F that'll output 0x6A.0x65 = 10110 and 0x0F16 = 1510. 0x6A16 = 10610 . We have that 10110 = 11001012 and 10610 = 11010102 . This way, applying the “exclusive or” operator we get:
Bitwise negation or one's complement operation The bitwise "negation" operator (~~~) is an unary operatorthat inverts the value of the bit. The operation is done bit by bit. If the bit is 1 then the operator outputs 0 otherwise if it is 0 then the operator outputs 1. It forms the one's complement of a given number.
For example, the sample given on Table 1 is ~~~0x65 that'll output 0xFFFFFF9a. 0x65 = 10110 and 0xFFFFFF9a16 = -10210. This way, applying the "negation" operator we get:
~~~ 01100101 = 10110 -------- 10011010 = -10210
Final notes notes I hope that you have gotten the principles behind the bitwise arithmetic operators.
Important: do not try to make sense of the encoder code because as the name says it's an encoder, so there are customizations implemented on it, that is, how to dispose the bytes into the output list is done according to the developer's will. That's why it's an encoder. Only who has the encoding pattern can decodes the encoded data! :-)
A good tip: use the computer calculator to exercise more examples. I use the Windows calculator in its scientific fashion/configuration. You can change its standard view through the View menu.
Ever wished you could have the latest version of Mozilla Firefox? Think no more. You actually can have it. Keep reading and you'll see how.
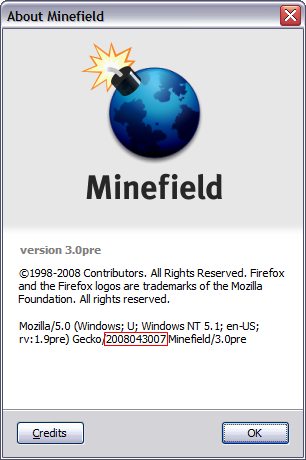
On the date of this post the latest version of Firefox that I'm running is the one shown on the following picture (I'm downloading right now the 20080507 nightly build):
As you can see my current version is the one from April, 30th. Look inside the red rectangle. I don't download the nightly build everyday.
One thing interesting is the name: Minefield. Believe me: It's not that minefield as the name states.
Nightly builds This is what the folks from the Mozilla developer division say about the nightly builds:
Nightly builds are created most weekdays from the previous day's work, these builds may or may not work. Use them to verify that a bug you're tracking has been fixed.
We make nightly builds for testing only. We write code and post the results right away so people like you can join our testing process and report bugs. You will find bugs, and lots of them. Mozilla might crash on startup. It might delete all your files and cause your computer to burst into flames. Don't bother downloading nightly builds if you're unwilling to put up with problems.
I've been using the nightly builds for a long time and from what I found you can have the latest innovations in browsing technologies without worrying about lots of bugs or crashes. Using a nightly build is perfect. You can use it for your day to day navigation. It's really stable. From what I remember it has crashed 2 or 3 times in a time span of more than 1 year. Besides that, no worries!
Firefox features I like most From the innovations and my own tweaks, the ones that I like most are:
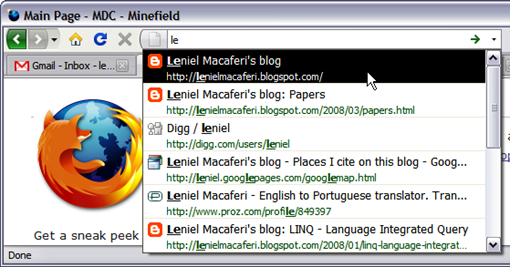
- URL auto-completion One of the greatest features (there are lots of them) is URL auto-completing - they call it "Location bar and auto-complete". Type the title or tag of a page in the location bar to quickly find the site you were looking for in your history and bookmarks. Favicons, bookmark, and tag indicators help you see where the results are coming from.
This is implemented through a lightweight database that stores the URLs already visited. The more you access a URL the high will be its rank in the list of visited URLs. You just start typing the address and instantly you get the URL you're after. You don't need to type the whole thing every time. It's a must. I use it all the time. See it in action:
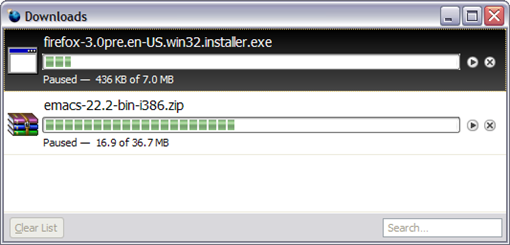
- New revamped Download Manager The Download Manager is fantastic too. You don't need to start your downloads all over again in case you interrupt them. You can resume from the point you stopped. You can check more info about its improvements in the next version of Firefox at the page Download Manager improvements in Firefox 3. See its face:
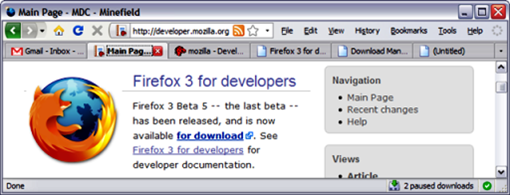
- More available screen size (this is my own tweak) More size to see the web page content. You can personalize your browser so that your toolbar buttons don't fill the space you could use to visualize content and more content. Check how I customize my browser so that I have the best fit:
I've shrunk the above window to show it here, but you have a big space to type your URLs in the location/address bar.
I don't have any toolbar. I just put all the buttons I use most on the left of the address bar and the standard menus on the right. To do this simply right-click on one of the menus and select "Customize...". From there you can change the disposition of the buttons. Click and hold one of the buttons and put it anywhere you want. As I did I put them on the left and right side of the address bar. I just don't use the standard toolbars that are: the Navigation toolbar and the Bookmarks toolbar. To not use them, uncheck them. What you gain? More space.
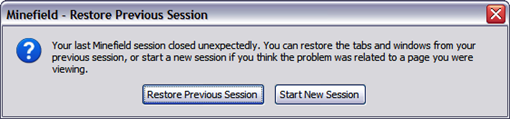
- Restore Previous Session Restore Previous Session is the other one that I think is really helpful. You see, while I was composing this post I had to get some screenshots. To do this I should have pressed the key Print Screen on the keyboard but instead I pressed the key Power that is just above the Print Screen one. What happened? My computer hibernated. I did this for three times in a row. The last one I hit the restart button on my machine while it was going to hibernate. I don't know why I did it. I lost all the applications that were in memory. Firefox was one of them. Now I just came back to continue typing this post and opened Firefox again. What did I get? The following dialog:
Clicking on Restore Previous Session, Firefox brought back all the tabs that were open the time the computer was turned off accidentally. Fantastic, isn't it? It can help a lot in case of power failure too.
The change from Internet Explorer to Firefox I remember that I was reluctant in changing from Internet Explorer to Firefox. I decided to try Firefox one day. I installed and used it a little bit and I didn't like it, so I uninstalled and continued using Internet Explorer. I don't remember exactly when I gave it a second chance, but the fact is that I gave and this time I think it is forever. After playing with it a little bit more I saw how customizable it was through add-ons, etc (e.g.: the tweak I did with the toolbars isn't possible with Internet Explorer).
After the changing I don't want to go back to IE. Firefox is much superior in quality and velocity. You navigate the internet really faster.
Remember one thing though: you should have a version of Internet Explorer in case you need it for a site that doesn't work well with Firefox. Yes, there are sites and forms that don't play well with Firefox yet. If you ever be in such a situation, just open IE and try with it. That's what I do and it has worked fine.
Nightly builds Nightly builds are the ones I use. Each day we have a new one. You can get it at the latest trunk page.
Final notes It's impossible to comment on every part of Firefox that I like. I hope that you could have gotten the notion of a few of the capabilities of this splendid piece of software. I think of Firefox as a work of art. In truth it's what it is: a work of art.
The open source community must be recognized as a powerful and expressive one. They are on the scene. Congratulations to everyone that helps make Firefox such an work of art. It's amazing to realize how a collaborative work has evolved impressively during the last years.
Folks, keep up the great job and continue innovating all the time. That's what makes someone like me write a post like this.

 The crescent demand for enterprise management software has as key factor big companies, which need to manage millions of records trying with that: find a better way of working with so great amount of information available in their huge databases and get to the target of their business.
The crescent demand for enterprise management software has as key factor big companies, which need to manage millions of records trying with that: find a better way of working with so great amount of information available in their huge databases and get to the target of their business. The
The